- 汉诺塔问题
- 斐波那契数
- n以内的素数
- 一些用过的内置函数,模块方法
- 8x8皇后问题
- 查找皇后位置的代码
- pickle模块
- Unicode编码
- 670 个常用 Python 库和示例代码
- 文档化开发–Epydoc
- 字典按键和值排序
一些Python练习题,只是写下来。
汉诺塔问题
汉诺塔问题是典型的递归思想问题
def Hanoi(a,b,c,n): ##所有铁片大在下小在上初始在a,最终如是放于c
if n==1:
print a,'->',c
else:
Hanoi(a,c,b,n-1) #将前n-1个盘子从a移动到b上
Hanoi(a,b,c,1) #将最底下的最大的盘子从a移动到c上
Hanoi(b,a,c,n-1) #将前n-1个盘子从b移动到c上
def calSteps(n): ##计算移动步数
return 2**n+1
if __name__=='__main__':
Hanoi('A','B','C',10)
Hsteps=calSteps(10)
print "we have %s steps" %Hsteps
斐波那契数
也是典型的递归思想
前两数之和即为下一个数
def Fibonacci(n): ##计算第n个Fibonacci数值
F_list=[]
if n==0 or n==1:
return n
else:
return (Fibonacci(n-1)+Fibonacci(n-2)) ##递归调用
if __name__=='__main__':
for i in range(7):
print Fibonacci(i)
n以内的素数
- 素数判断
# 1:
def is_prime(n):
if n <= 1:
return False
for i in range(2, int(math.sqrt(n)) + 1):
if n % i == 0:
return False
return True ##数字为2,3时直接跳过for循环(因为range没有迭代返回)
# 2:
def is_prime(n):
#if n==2 or n==3:
#return True
for num in range(2, int(math.sqrt(n))+1): #能跳过该循环的只有2,3
if n % num == 0 and n != num:
break
elif n % num != 0 and num == (int(math.sqrt(n))):
return True
return True
简短的求100以内素数, 使用filter将100以内的质数挑选出来:
import math
def func_get_prime(n):
return filter(lambda x: not [x%i for i in range(2, int(math.sqrt(x))+1) if x%i ==0], range(2,n+1))
print func_get_prime(100)
下面这段程序有问题,找时间改:
# 判断n以内素数
import math
# 在一般领域,对正整数n,如果用2到sqrt(2)之间的所有整数去除,均无法整除,则n为质数。
# 质数大于等于2 不能被它本身和1以外的数整除
def is_prime(n):
list_num = []
for i in range(2, n):
for num in range(2, int(math.sqrt(n))+1):
if i % num == 0:
break
list_num.append(i)
return list_num
# call function:show all prime little than n
# print is_prime(100)
注意:if i % num == 0 and i != num:中添加and i != num:为了防止2,3不被当做质数;
elif i % num != 0 and num == (int(math.sqrt(i))):中添加and num == (int(math.sqrt(i)))防止质数被多次加入质数队列 and 非2的倍数的非质数(eg:15)被加入质数队列。
一种速度非常快的求解1000000以内素数方法
def primesqrt(n):
result = list()
result.append(2)
result.append(3)
for i in xrange(5,n+1,2):
for j in xrange(2,int(sqrt(i))+2):
#for j in range(2,(i>>4)+1):
if i%j == 0:
break
else:
result.append(i)
return result
一些用过的内置函数,模块方法
- open(‘filename’,’r,w,a’) return a File Objects.
- file.write(string)
- file.writelines(sequence)
- file.readline()返回一行的字符串
-
file.readlines()返回包含文件所有内容的字符串列表,每个元素是一行字符创
- string.join(words[,sep]) eg:s=string.join(string.split(s,sep),sep)
- str.join(iterable)连接List成为以str间隔的字符串 iterable:List,String,Tuple etc;
- string.strip()返回删除字符串头尾空白后的字符串
下面的是的built-in types:

- str.endswith(suffix[, start[, end]]) Return True if the string ends with the specified suffix, otherwise return False. suffix can also be a tuple of suffixes to look for. With optional start, test beginning at that position. With optional end, stop comparing at that position.
-
str.startswith(prefix[, start[, end]]) Return True if string starts with the prefix, otherwise return False. prefix can also be a tuple of prefixes to look for. With optional start, test string beginning at that position. With optional end, stop comparing string at that position.
- sorted()
sorted(iterable[, cmp[, key[, reverse]]]) Return a new sorted list from the items in iterable. The optional arguments cmp, key, and reverse have the same meaning as those for the list.sort() method (described in section Mutable Sequence Types). cmp specifies a custom comparison function of two arguments (iterable elements) which should return a negative, zero or positive number depending on whether the first argument is considered smaller than, equal to, or larger than the second argument: cmp=lambda x,y: cmp(x.lower(), y.lower()). The default value is None. key specifies a function of one argument that is used to extract a comparison key from each list element: key=str.lower. The default value is None (compare the elements directly). reverse is a boolean value. If set to True, then the list elements are sorted as if each comparison were reversed. In general, the key and reverse conversion processes are much faster than specifying an equivalent cmp function. This is because cmp is called multiple times for each list element while key and reverse touch each element only once. Use functools.cmp_to_key() to convert an old-style cmp function to a key function. The built-in sorted() function is guaranteed to be stable. A sort is stable if it guarantees not to change the relative order of elements that compare equal — this is helpful for sorting in multiple passes (for example, sort by department, then by salary grade)
- list.sort()
The sort() method takes optional arguments for controlling the comparisons. cmp specifies a custom comparison function of two arguments (list items) which should return a negative, zero or positive number depending on whether the first argument is considered smaller than, equal to, or larger than the second argument: cmp=lambda x,y: cmp(x.lower(), y.lower()). The default value is None. key specifies a function of one argument that is used to extract a comparison key from each list element: key=str.lower. The default value is None. reverse is a boolean value. If set to True, then the list elements are sorted as if each comparison were reversed.
第一种:
string = '''
the stirng
Has many
line In
THE fIle
jb51 net
'''
list_of_string = string.split()
print list_of_string #将字符串分离开,放入列表中
print '*'*50
def case_insensitive_sort(liststring):
listtemp = [(x.lower(),x) for x in liststring] #将字符串列表,生成元组,(忽略大小写的字符串,字符串)
listtemp.sort() #对元组排序,因为元组为:(忽略大小写的字符串,字符串),就是按忽略大小写的字符串排序
return [x[1] for x in listtemp]#排序完成后,返回原字符串的列表
print case_insensitive_sort(list_of_string)#调用起来,测试一下
第二种:使用内建函数 sorted(iterable[,cmp[, key[,reverse]]])
string = '''
the stirng
Has many
line In
THE fIle
jb51 net
'''
list_of_string = string.split()
print list_of_string #将字符串分离开,放入列表中
print '*'*50
def case_insensitive_sort2(liststring):
return sorted(liststring,key = str.lower)
print case_insensitive_sort2(list_of_string)#调用起来,测试一下
第三种:使用list的sort方法
string = '''
the stirng
Has many
line In
THE fIle
jb51 net
'''
list_of_string = string.split()
print list_of_string #将字符串分离开,放入列表中
print '*'*50
def case_insensitive_sort3(liststring):
liststring.sort(cmp=lambda x,y: cmp(x.lower(), y.lower()))
case_insensitive_sort3(list_of_string)
print list_of_string
8x8皇后问题
在8X8格的国际象棋上摆放八个皇后,使其不能互相攻击,即任意两个皇后都不能处于同一行、同一列或同一斜线上,问有多少种摆法。
参考:CDays-3 习题三 (八皇后问题)及相关内容解析。Python 基础教程
可以肯定,一行有且只有一个皇后,每一列有且只有一个皇后。 我们先预想一个循环,对每一排的每个位置编号0~7 。 我们对每一个位置都应该有可行性判定,即该位置的上下左右,正负对角线有没有皇后,如果有就跳过该位置。
col = [] #矩阵列的列表,存储皇后所在列,若该列没有皇后,则相应置为1,反之则0
row = [] #矩阵行的列表,存放每行皇后所在的列位置,随着程序的执行,在不断的变化中,之间输出结果
pos_diag = [] #正对角线上,i-j的值恒定,范围是-7~0~7,使用b(i)+7将其统一到0~14
nag_diag = [] #负对角线上,i+j的值恒定,范围是0~14
查找皇后位置的代码
for j in range(0, 8): #依次尝试0~7位置
if col[j] == 1 and pos_diag[i-j+7] == 1 and nag_diag[i+j] == 1:
#若该行,正对角线,负对角线上都没有皇后,则放入i皇后
row[i] = j
col[j] = 0 #调整各个列表状态
pos_diag[i-j+7] = 0
nag_diag[i+j] = 0
if i < 7:
do_queen(i+1) #可递增或递减
else:
print row #产生一个结果,输出
col[j] = 1 #恢复各个列表状态为之前的
pos_diag[i-j+7] = 1
nag_diag[i+j] = 1
pickle模块
python的pickle模块实现了基本的数据序列和反序列化。通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储;通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
pickle.dump(obj, file, [,protocol])file必须有write()接口, file可以是一个以’w’方式打开的文件或者一个StringIO对象或者其他任何实现write()接口的对象
import pickle
data1 = {'a': [1, 2.0, 3, 4+6j],
'b': ('string', u'Unicode string'),
'c': None}
selfref_list = [1, 2, 3]
selfref_list.append(selfref_list)
output = open('data.pkl', 'wb')
# Pickle dictionary using protocol 0.
pickle.dump(data1, output)
# Pickle the list using the highest protocol available.
pickle.dump(selfref_list, output, -1)
output.close()
pickle.load(file)注解:从file中读取一个字符串,并将它重构为原来的python对象。 file:类文件对象,有read()和readline()接口。
# 使用pickle模块从文件中重构python对象
import pprint, pickle
pkl_file = open('data.pkl', 'rb')
data1 = pickle.load(pkl_file)
pprint.pprint(data1)
data2 = pickle.load(pkl_file)
pprint.pprint(data2)
pkl_file.close()
Unicode编码
编/解码与乱码
str利用decode方法根据str的编码将其解码为unicode字符串类型,然后利用encode根据特定的编码将unicode字符串类型转换为特定的编码。python中str和unicode属于两种不同的类型.
一般情况下window默认编码gbk,linux默认编码utf8. Python编程中:
-
系统编码: 默认写源码的编辑器的编码方式。它代表源码文件内的所有内容都是根据词方式编码成二进制码流。存入到磁盘中的。linux下通过locale命令查看。
-
python编码: 指python内设置的解码方式。如果不设定的话,python默认的是ascii解码方式。如果python源代码文件中不出现中文的话,这个地方怎么设定应该不会问题。
设定方法:在源码文件开头(一定是第一行):#--coding:UTF-8--,源码文件的设置解码方式是UTF-8 或者
import sys
reload(sys)
sys.setdefaultencoding('UTF-8')
-
文件编码:
文本的编码方式,linux下vim利用set fileencoding查看。
一般情况下输出乱码的原因就是 没有按照系统解码的方式进行编码。
比如print s, s类型为str,linux系统下系统默认编码为utf8编码,s在输出前就应该编码为utf8。如果s为gbk编码就应该这样输出。print s.decode(‘gbk’).encode(‘utf8’)才能输出中文。
window下面情况相同,window默认编码为gbk编码,所以s输出前必须编码为gbk。
python处理中一般处理unicode类型。这样输出前直接编码即可。
编码探测器
chardet 官网地址
python setup.py --help #查看帮助
安装简单:
python setup.py install
670 个常用 Python 库和示例代码
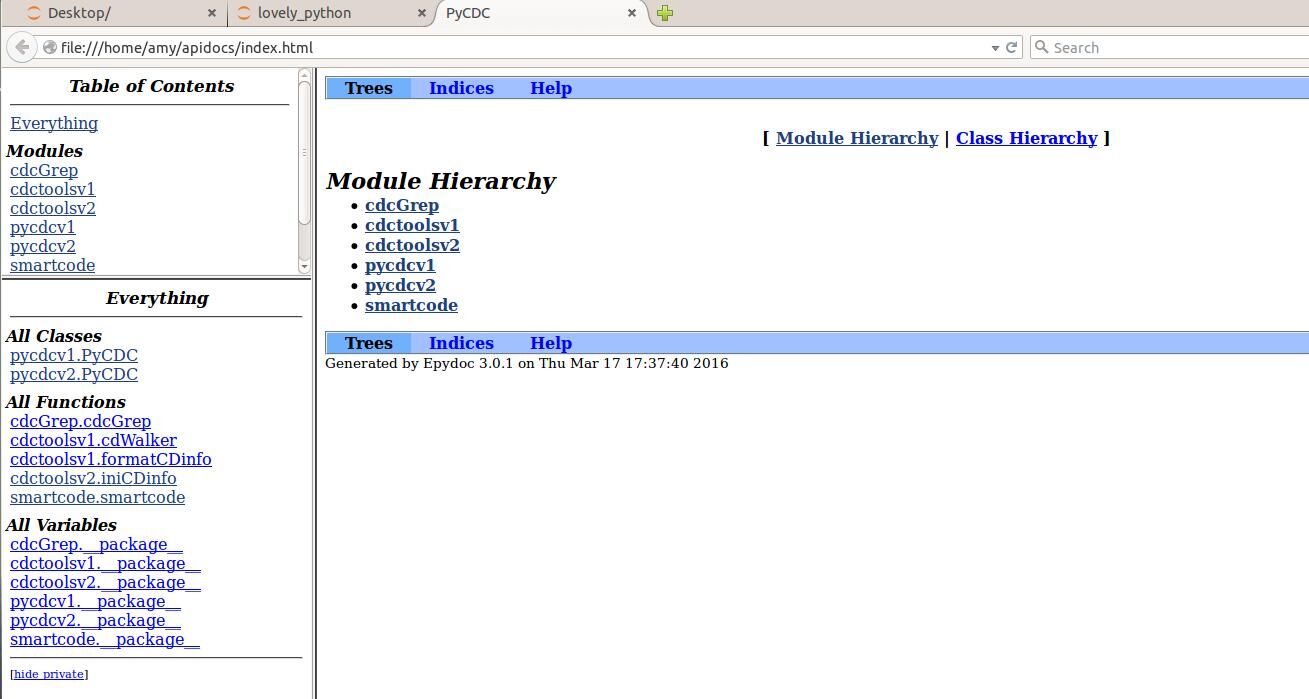
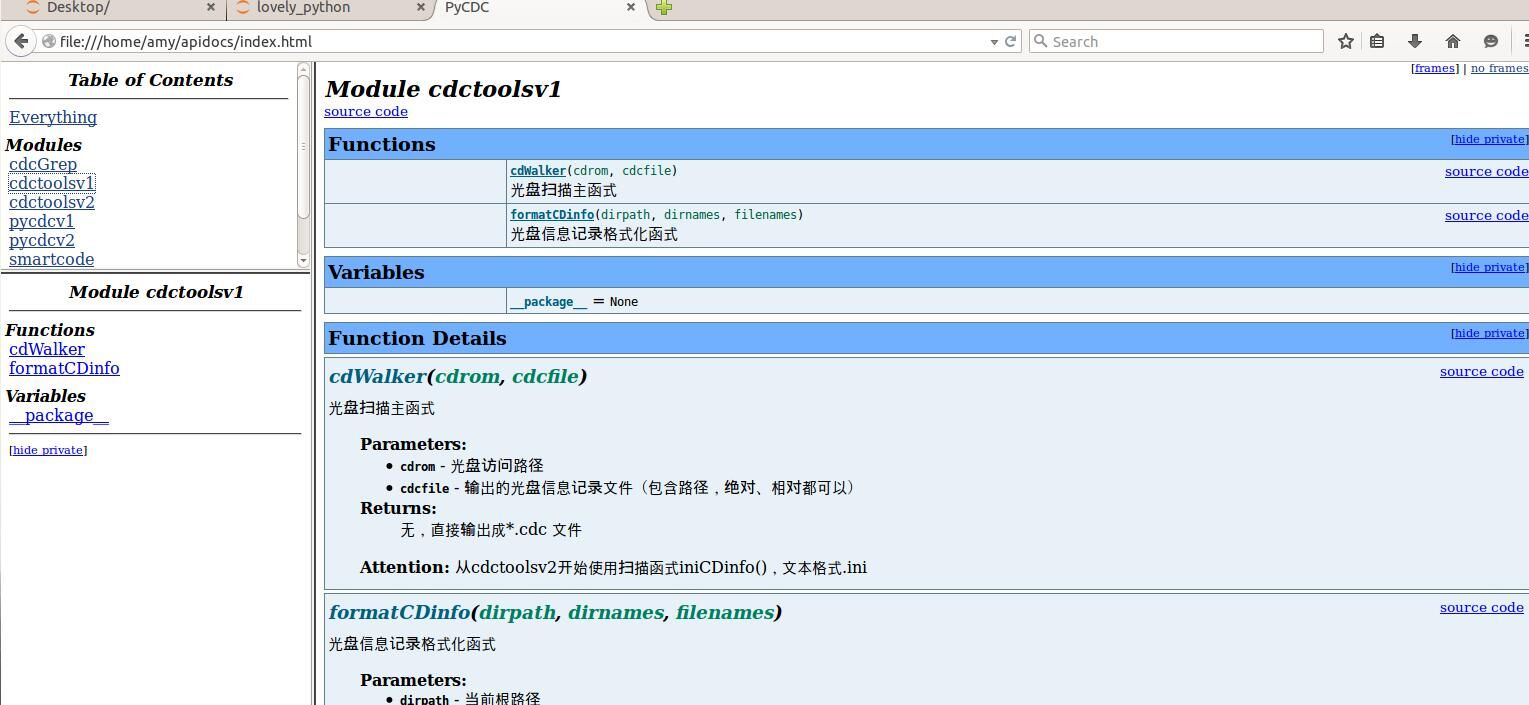
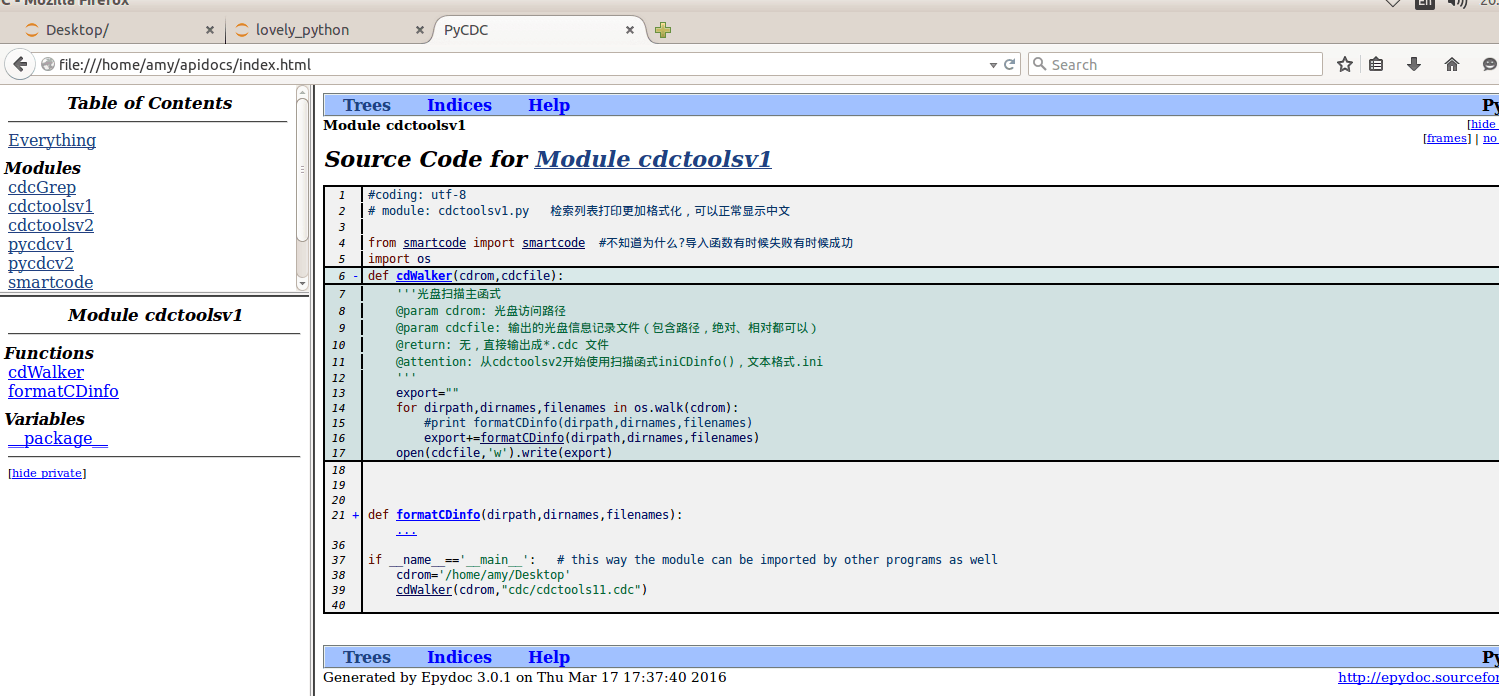
文档化开发–Epydoc
- 安装
# Download an epydoc source distribution to a directory of your choice, and uncompress it.
[/tmp]$ wget -q http://prdownloads.sourceforge.net/epydoc/epydoc-3.0.1.tar.gz
[/tmp]$ gunzip epydoc-3.0.1.tar.gz
[/tmp]$ tar -xvf epydoc-3.0.1.tar
# Use the setup.py script in the eydoc-3.0.1/ directory to install epydoc.
[/tmp]$ cd epydoc-3.0.1/
[/tmp/epydoc-3.0.1]$ su
Password:
[/tmp/epydoc-3.0.1]# python setup.py install
running install
running build
[...]
copying build/scripts/epydoc -> /usr/bin
changing mode of /usr/bin/epydoc to 100775
[/tmp/epydoc-3.0.1]# cd ..
[/tmp]#
# If you'd like to keep a local copy of the documentation, then copy it to a permanant location, such as /usr/share/doc/. You may also want to copy the man pages to a permanant location, such as /usr/share/man/.
[/tmp]# cp -r epydoc-3.0.1/doc/ /usr/share/doc/epydoc/
[/tmp]# cp epydoc-3.0.1/man/* /usr/share/man/
# Once epydoc is installed, you can delete the installation directory and the source distribution file.
[/tmp]# rm -r epydoc-3.0.1
[/tmp]# rm epydoc-3.0.1.tar
- 配置
新建一个epydoc.cfg配置文件
[epydoc]
# project info
name:PyCDC
url:
# the file\dir to be process
modules: /home/amy/Desktop/pycdcv1.py,/home/amy/Desktop/pycdcv2.py,/home/amy/Desktop/cdctoolsv1.py,/home/amy/Desktop/cdctoolsv2.py,/home/amy/Desktop/smartcode.py,/home/amy/Desktop/cdcGrep.py
# use html format,output to apidocs/ dir
output:html
target:apidocs/
# direct Graphviz dot. dir,generate UML relation_graph!
graph:all
dotpath: /usr/bin/dot
- 生成文档
amy@ubuntu-host2:~$ epydoc -h
amy@ubuntu-host2:~$ epydoc --config epydoc.cfg
字典按键和值排序
python 字典(dict)的特点就是无序的,按照键(key)来提取相应值(value),如果我们需要字典按值排序的话,那可以用下面的方法来进行:
- 按照value的值从大到小
dic = {'a':31, 'bc':5, 'c':3, 'asd':4, 'aa':74, 'd':0}
dict= sorted(dic.iteritems(), key=lambda d:d[1], reverse = True)
print dict
输出的结果:
[('aa', 74), ('a', 31), ('bc', 5), ('asd', 4), ('c', 3), ('d', 0)]
下面我们分解下代码:
dic.iteritems() 得到[(key,value)]的列表list。
sorted():通过key这个匿名函数,指定排序是按照value,也就是d[1]的值来排序。
reverse = True表示是需要翻转的,默认是从小到大,翻转的话,那就是从大到小。
- 字典按键(key)排序
dic = {'a':31, 'bc':5, 'c':3, 'asd':4, 'aa':74, 'd':0}
dict= sorted(dic.iteritems(), key=lambda d:d[0]) d[0]表示字典的键
print dict